Figure 1: 1601 Mercator-Hondius
by Tim Bray, Senior Vice President - Technology, Open Text Corporation, email: tbray@opentext.com
"When you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot express it in numbers, your knowledge is of a meager and unsatisfactory kind; it may be the beginning of knowledge, but you have scarcely in your thoughts advanced to the state of science." - Lord Kelvin
This paper presents some difficult qualitative questions concerning the Web, and attempts to provide some partial quantitative answers to them. It uses the numbers in these answers to drive some 3-D visualizations of localities in the Web.
Since the first robot was launched on Saint Valentine's Day 1995, the Open Text Index software has examined millions of pages and maintained an ever-growing inventory of information about them.
This effort has been, from the outset, marketing-driven. Open Text is a long-time vendor of search and retrieval technology, and the WWW became, during the course of 1994, the world's largest and most visible retrieval problem. Failing to have attacked it would have been a vote of no confidence in our own technology.
As a business exercise, it has been successful. Open Text's Livelink Search and Livelink Spider are leaders in the fast-growing market for Web site indexers . Considered as an intellectual effort, it has been less than satisfying. We advertise our work as an Index of the WWW - and yet it covers much less than the whole. Our difficulty is similar to that of the cartographers of centuries past, struggling with the task of mapping territories which are still largely unknown. Observe, for example, the large Terra Australis Incognita in Figure 1.
Figure 1: 1601 Mercator-Hondius
This paper uses the resources of the Open Text Index to derive some approximations to the answers.
The information on which this report is based was extracted in November 1995, when the Open Text Index covered the content of about 1.5 million textual objects retrieved from the WWW. Today, the sample would be much larger. To keep things simple, we'll call these objects "pages". The pages were identified and retrieved as follows:
http,
gopher, and ftp style anchors.
Those that are not duplicates of already-indexed pages are queued for addition
to the Index.
Nobody can say how good a sample this is of the whole Web. However, the basic statistics presented below about page size and contents have not changed much since we started measuring them, during which time the Index has grown by more than an order of magnitude. Thus, while there is probably systematic bias in these numbers, it does not seem a function of the sample size.
The following are personal intuitions about the sample, which should be taken as speculation rather than ex cathedra wisdom:
Bear in mind, once again, that these numbers are the result of a snapshot taken in November 1995; recent estimates are in excess of 50 million.
This includes only URLs that begin with http, ftp,
or gopher. To find duplicates we apply the following
heuristics:
/a/./b/./c and /a/d/../b/e/../c are converted to
/a/b/c.The servers are counted simply by syntactic processing of URLs; there is no guarantee (or expectation) that all of them are actually valid.
Should the two terms "Web site" and "Web server" mean the same thing? Clearly, www.berkeley.edu and web.mit.edu are two different sites. But are Berkeley's Academic Achievement Division on server www.aad.berkeley.edu and Academic Preparation and Articulation on ub4.apa.berkeley.edu different? At Open Text, the search engine and the main corporate site have different webmasters, run on different computers, and exist to serve quite different purposes.
Formalizing the notion of a "site" causes some information loss, but allows us to develop some useful statistics. The current formalization (implemented in perl) may be summarized as:
Thus, ucla.edu, ox.ac.uk,
sun.com, cern.ch, and arl.army.mil
are all "sites."
These rules clearly underestimate the number of independently-operated "sites;" for example they make no distinction, at the "site" named UIUC, between the University of Illinois Press and NCSA. However, they also usefully conflate many superficially-different aliases, and capture something close enough to the human conception of a "site" to be useful, so we shall use them as the basis for quite a number of statistics.
The size of the average page has consistently been between 6K and 7k bytes during the entire lifetime of the Index. The size has fallen slightly as the sample size has grown, from just under 7000 to about 6500 at the time of writing. This amounts to about 1,050 "words," depending of course on how one defines a word - we use an indexable token beginning with an alphabetic character. Figure 2 illustrates the clustering in this distribution, and the presence of a significant number of very large pages.
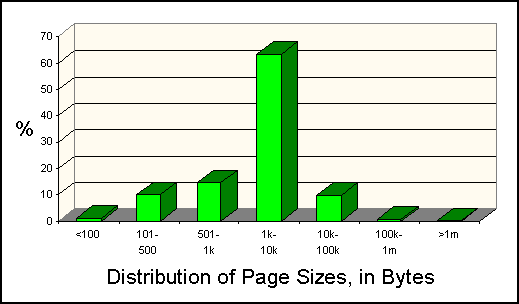
Figure 2: Page Size Distribution
The page sizes are highly variable, as illustrated in Table 1, which covers one snapshot of 1.524 million pages.
| Mean | 6518 |
| Median | 2021 |
| Standard Deviation | 31678 |
The Web is quite graphically rich. Figure 3 shows that just
over 50% of all pages contain at
least one image reference. It is interesting to note that about 15% of pages
contain exactly one image. Quite likely, for many of the pages that contain
large numbers of images, those images are in fact typographical marks of the "reddot.gif"
( ) variety.
) variety.
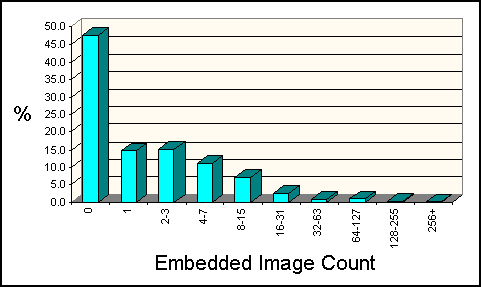
Figure 3: Distribution of Embedded Image Counts
As Figure 4 shows, a large majority (just under 75%) of all pages contain at least one URL. Note that this includes local ("#"-prefixed) URLs; still, it is fair to conclude that pure "leaf" pages are in the minority. It is fairly uncommon (less than 10%) for a page to contain exactly one URL.
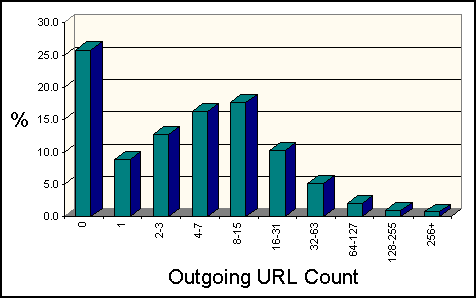
Figure 4: Distribution of Embedded URL Counts
At one point in the history of the Open Text Index, we built a search function that would, for any URL, retrieve all pages that contained references to that URL. This was easy to implement simply by doing a full-text search for the page's URL, but the results were disappointing. The vast majority of pages proved to have no incoming links at all. We realized quickly that the problem is that most WWW links are relative rather than absolute. What we had discovered, in fact, is that most pages are pointed-to only by other pages at the same site.
When we think of Web connectivity, we are more interested in inter-site linkages. Our analysis, summarized in Figure 5, reveals some surprising facts.
First, a large majority of sites (over 80%) are pointed to by "a few" (between one and ten) other sites. Some sites are extremely "visible," with tens of thousands of other sites pointing to them. But a few (just less than 5%), oddly enough, have no other sites pointing to them. Presumably, these are sites that have been placed in the Index via the submission process, but are not, in one important sense, truly "connected" to the Web.
Second, web sites in general do a poor job of providing linkage to other web sites. Almost 80% of sites contain no off-site URLs. Clearly, a small proportion of web sites are carrying most of the load of hypertext navigation.
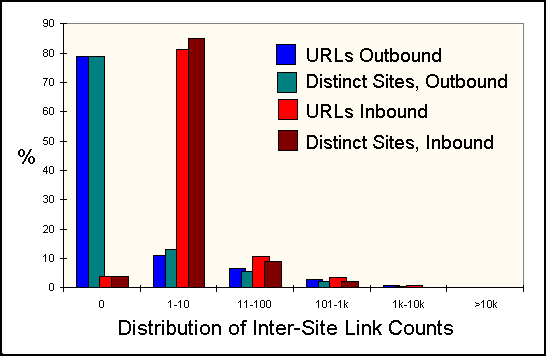
Figure 5: Inter-Site Link Count Distribution
The observation that there are sites with thousands (even tens of thousands) of incoming URLs is interesting. These sites, highlighted in Figure 6, must be deemed unusually "visible." They are, in some sense, at the centre of the Web. Perhaps not surprisingly, UIUC leads the list, illustrated in the chart below, of such sites. The ordering is somewhat different depending on whether it is done by number of incoming off-site URLs, or the number of sites they come from. For example, the European Molecular Biology Laboratory in Heidelberg and the Geneva University Hospital both make the top-URL list by virtue of thousands of off-site pointers from sites such as Argonne National Labs.
With these exceptions, the top sites are a list of well-known universities, organizations (CERN and the World-Wide Web Consortium), and a few companies. The only commercial sites which make the top-10 list ranked by number of other sites are Yahoo!, number 3, and Netscape, number 5.
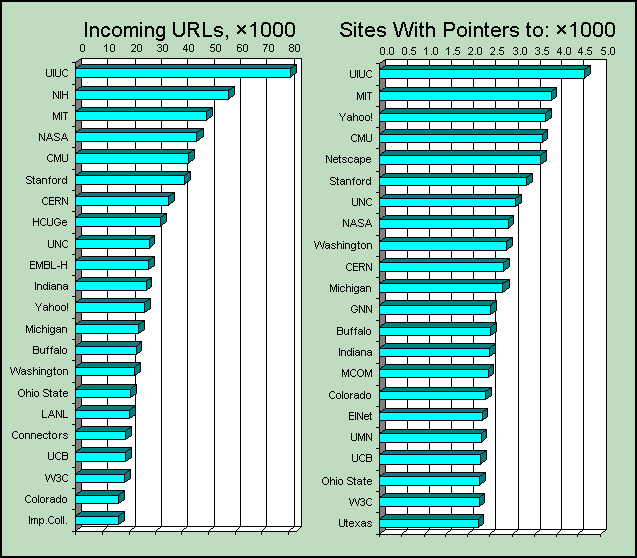
Figure 6: Most Visible Sites
Reversing this statistic, we next rank Web sites by the number of outgoing URLs, and number of other sites they point to. At the top of the list are the relatively few sites who, as noted above, carry most of the Web's navigational workload. This statistic, illustrated in Figure 7, is somewhat flawed. There are a small number of sites, not listed here, each of which contain more off-site pointers than all of these combined. These would be the Web indexers such as Open Text, Lycos, and Infoseek. Not surprisingly, the list, whether ranked by URL count or number of sites pointed to, has Yahoo! in position 1. There are a few other surprises here; but in general, we think that all the sites on this list deserve respect; they provide the silken strands that hold the Web together.
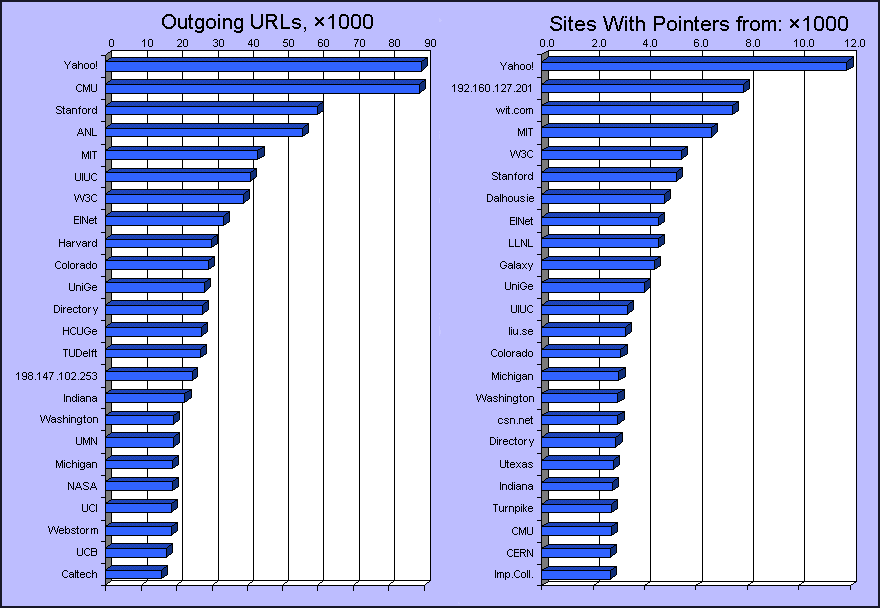
Figure 7: Most Lumous Sites
HTML is said to be the language of the Web. However, its most important underlying protocol, HTTP, can be used to transport anything. Unfortunately, the Open Text Index does not capture the MIME Content-Type that is associated with each page by its server. Thus, we can only use heuristics to approximate the measurements of data formats. The Open Text Index explicitly excludes data formats that are largely non-textual (graphics, PostScript, WP documents). Over the universe of textual pages on the Web, we think the following are fair:
Based on this heuristic, the analysis, summarized in Figure 8, shows that a large majority of pages (over 87%) are making some effort to present themselves as HTML. A pleasing 5% have gone so far as to include an SGML declaration - of course this is no guarantee that they are actually validated against any particular DTD. About one-eighth of all pages are either raw text or are making no effort whatsoever to be HTML.
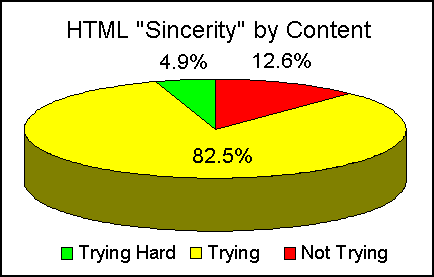
Figure 8: HTML Sincerity
There is one other source of information about data types: the file extension. Over 80% of all Web pages are likely HTML because they carry no file extension or are explicitly identified as such by extension. The 18% of files that are explicitly identified by extension as something other than HTML is, amusingly, larger than the proportion of pages that contain no <TITLE> tag.
Figures 9 and 10 show which other file extensions most often appear in URLs. Not surprisingly, GIF graphics and Text files are the most popular, each at about 2.5%. PostScript, JPEG, and HQX files all hover just over 1%. All other formats are below 1%.
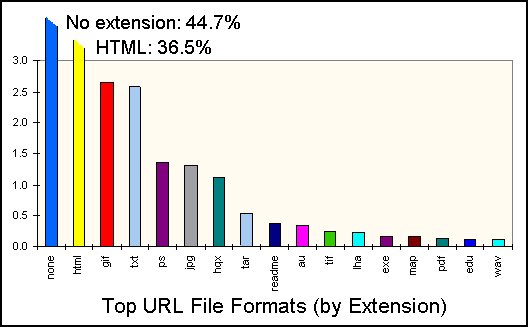
Figure 9: Popular File Formats, by Extension
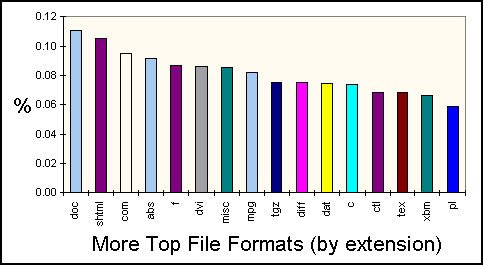
Figure 10: More Popular File Formats, by Extension
The Web, when you're in it, feels like a place. It manifests, however, as a sequence of panels marching across your screen. This leads to an absence of perspective, of context, and finally, of comfort. Most of us who have worked with the Web, in particular those who have read Gibson or Stephenson, want to see where we are. "Visualizing the Web" is a perennial on the program of these conferences.
The database behind the Open Text Index, and behind the statistics in this paper, can be used to drive Web visualization. Some of the principles we adopt are:
Let us examine some database-driven visualizations. The graphics are captured from VRML representations generated dynamically from the Open Text Index database, viewed with Paper Software's WebFX plug-in (now appearing as Netscape's Live3D). We represent sites as ziggurats crowned with globes: the diameter expresses the number of pages, the height the visibility, the size of a globe floating overhead the luminosity, and the colour the site's domain. We distribute sites in space based on the strength of the linkages between them.
Figure 11 tells us that UIUC (including NCSA, of course) is the Web's most visible site. Neither Stanford nor CMU is quite as visible, but both cast more light on the Web. Yahoo! is most luminous of all.

Figure 11: Some Well-Known Sites
The sites most closely linked to NASA, shown in Figure 12, are a mixed bag; Government sites are red, academic sites green and nonprofit organizations golden. CMU's navigational strength is obvious once again, as is the that of the Web Consortium site. NASA itself provides relatively little navigational help.

Figure 12: NASA's Neighborhood
Figure 13 shows the four most visible sites on the Web. The tiny red dot above the "i" in "nih" reveals that very visible site's poverty in outgoing links. UIUC's visibility and CMU's luminosity are obvious.
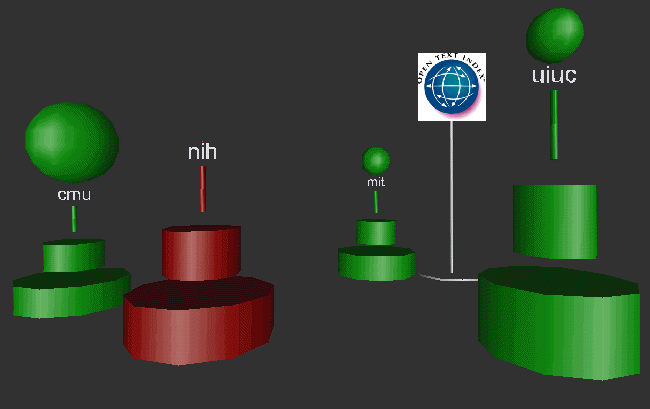
Figure 13: At the Very Centre
The scene in Figure 14 starts to give a feeling for the Web's chaos. Commercial sites are rendered in blue, and network infastructure in cyan. The navigational strength of Yahoo! and Einet are obvious.

Figure 14: A Wider View
Figure 15's view, spiralling out from UIUC, has a European slant. Particularly interesting is the fact that the highly-illuminated European Molecular Biology Laboratory in Heidelberg casts almost no light; the tiny dot representing its Web-luminosity may be visible in some viewers above and to the left of the "i" in "heidelberg."

Figure 15: The Web is World-Wide, After All
The sites that are most closely linked to the Playboy site, illustrated in Figure 16, provide an interesting study in contrast. CMU, MIT, and UCSD seem to have about the same number of pages. However, CMU leads MIT and then UCSD in both visibility and luminosity.

Figure 16: Friends of Playboy
At the moment, we don't know very much about the Web. This statistical lore in this paper may be generated straightforwardly (at the cost of considerable computation) from a properly structured Web Index. We would like to devise a way to automate the generation of these statistics and, in particular, their graphical representations.
Techniques for presenting this information automatically, dynamically, compactly, and three-dimensionally are a significant subgoal of the larger campaign to build a working cyberspace. That in itself is a sufficient motivation for further work on the problem.
None of this would have been possible without the data gathered via the superhuman efforts of the Web Index team.
Thanks are also due to Tamara Munzner for provoking thought, and to Lilly Buchwitz for polishing language. Thanks also to James Hess and the Heritage Map Museum for the use of the "Typis Orbis Terrarum" map.
Tim Bray, Open Text Corporation, 101 - 1965 West Fourth Avenue, Vancouver, B.C., Canada, V6J 1M8, tbray@opentext.com Tim Bray was born in Canada, brought up in Lebanon, and graduated
from the University of Guelph in 1981. After on-the-job training
from Digital and GTE, he became Manager of the New Oxford English
Dictionary Project at the University of Waterloo in 1987. The
technology created on that project was the founding basis of Open
Text Corporation. He has published on the subjects of text
databases, philology, music, and the Web in the ACM Transactions
on Office Information Systems, the Toronto Globe and Mail, The
Absolute sound, and Wired. His current interest is creating an
immersive three-dimensional version of the Web.
Tim Bray was born in Canada, brought up in Lebanon, and graduated
from the University of Guelph in 1981. After on-the-job training
from Digital and GTE, he became Manager of the New Oxford English
Dictionary Project at the University of Waterloo in 1987. The
technology created on that project was the founding basis of Open
Text Corporation. He has published on the subjects of text
databases, philology, music, and the Web in the ACM Transactions
on Office Information Systems, the Toronto Globe and Mail, The
Absolute sound, and Wired. His current interest is creating an
immersive three-dimensional version of the Web.{kind=link}